
QEMU (Quick Emulator) is a free and open-source system emulator. It allows users to emulate a complete machine and operating system (the “guest”) on an existing piece of hardware (the “host”) with very minimal effort. Since QEMU is a complete hypervisor, it doesn’t require the host and guest machine to run the same operating system, or even use the same processing architecture; a user could install and run a complete Debian ARM system, with its own virtual CPUs and memory, on an Ubuntu x86 host. QEMU can also take advantage of Kernel-based Virtual Machine (KVM) CPU virtualization extensions to provide a massive speed boost, as long as the host and guest machine use the same architecture, such as x86 or ARM.
However, there are some cases when a user might not want to utilize KVM alongside QEMU; such as when performing selective symbolic execution, and other types of dynamic binary analysis. Since KVM passes off most computation to the Kernel (and the processor itself using virtualization extensions), it hides much of the underlying operation of the guest operating system from the host operating system. Thus, analysis programs such as PANDA and S2E which leverage the power of QEMU to glimpse into the guest operating system, programs, and data, are incompatible with KVM. Until recently, however, QEMU did not support running Windows x86 64-bit guests in pure emulation (non-KVM) mode due to a rather complex bug. The bug, and its fix, are detailed in this blog post.
Kernel Patch Protection (PatchGuard)
On 64-bit systems, Microsoft Windows utilizes a technology called Kernel Patch Protection, or PatchGuard, to ensure that programs don’t modify (i.e. “patch”) critical parts of the kernel (the core of the operating system). If it does detect such a modification, it will shut down the system (using a blue screen / stop error). This blog post won’t address the efficacy or security of Kernel Patch Production — rather, it will focus on some of its implementation and how it causes problems with QEMU.
PatchGuard works using a large amount of security through obscurity: heavy obfuscation, very little documentation, and, most importantly for our purposes, self-modifying code. Self-modifying code is intuitively named because it is code which modifies itself as part of its execution, thus somehow changing its execution path in real-time. It’s difficult to follow and difficult to debug, which may be why it is employed by PatchGuard. In any case, x86 self-modifying code provides some unique challenges for any emulator, QEMU or otherwise.
ARM and Self-Modifying Code
ARM is a computing architecture commonly used by embedded and mobile devices because of its simplicity and low power consumption. Most smartphones, tablets, smartwatches, and even some small laptops (such as Chromebooks) use ARM-based processors. Many ARM processors contain a cache of instructions, called the ICache, which it has recently executed or will execute, to speed up the execution process. These processors also contain a data cache, called the DCache, which caches program data.
When executing self-modifying code, such a processor writes a data change to the DCache, but RAM and/or the ICache are not guaranteed to be synchronized correctly. To solve this problem, the ARM specification requires programs which contain self-modifying code to both clean the DCache (e.g. ensure that the modified data is written to memory) and invalidate the section of the ICache which contains modified instructions before attempting to execute the modified instructions. This ensures that the self-modifying write makes it through to RAM and the relevant instructions cached in the ICache are updated before the modified instructions are actually executed.
Edit: Thanks to Joe Tanen for pointing out that isb alone is not enough to fully flush the instruction pipeline after a self-modifying write. This section has been updated to reflect that.
x86 and Self-Modifying Code
x86 is an architecture which is much more complex than ARM, and contains more features and optimization which support fully-featured operating systems. For this reason, it is the predominant architecture for desktops, laptops, and servers. However, x86 self-modifying code is much more difficult to handle for an emulator than ARM, as x86 handles self-modifying code using hardware mechanisms, omitting the need for the program to follow an explicit cache flush pipeline. Thus, it’s up to QEMU to detect self-modifying code and handle it appropriately.
QEMU
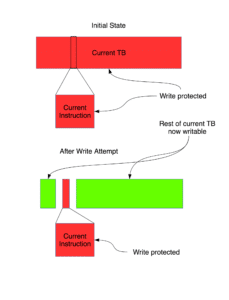
The way QEMU handles such code (in x86) is by write-protecting the memory page containing the current Translation Block (the current block of instructions translated from the guest’s architecture to the host’s architecture that are queued for execution) so that the executing program cannot write to instructions that are about to be executed. If the program does try to do this, QEMU catches the write, splits the Translation Block (TB) into the current instruction, and everything after/before the current instruction, and enables writes to the latter segment (Figure 2). This ensures that the currently executing instruction remains write-protected, while allowing it to modify other instructions in the current TB.
Once the TB has been fixed, QEMU then resumes CPU state to immediately before the instruction which tried to do the self-modifying write. The instruction should now proceed as normal, since the destination should now be writable. It turns out, however, that this can cause some issues in very specific situations, since memory isn’t reset before the resume. Consider when the guest machine tries to do an unaligned write to memory which happens to span two Translation Blocks. Here’s the section of code from QEMU where it handles such a special case:
for (i = DATA_SIZE - 1; i >= 0; i--) {
/* Little-endian extract. */
uint8_t val8 = val >> (i * 8);
/* Note the adjustment at the beginning of the function.
Undo that for the recursion. */
glue(helper_ret_stb, MMUSUFFIX)(env, addr + i, val8,
oi, retaddr + GETPC_ADJ);
}
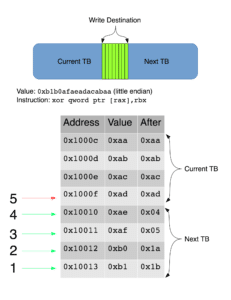
Essentially, it splits the write (8 bytes in the case of a qword write) into eight one-byte writes, in reverse order (from end to start). Consider the situation where the write spans two TBs, where the current TB is first (Figure 3). The first four writes would successfully execute, as they are not writing to the current TB, but the fifth write (the fourth byte in sequential order) would try to write to the current TB, and QEMU would go through the above unprotect process, and reexecute the unaligned write. However, since the first four writes are not invalidated or undone in any way, QEMU resumes to before any of the one-byte writes happened, and these first four writes are rewritten, but not necessarily with the same values.
This wouldn’t be an issue if the instruction was a simple mov, as the bytes would just be written twice to memory; the end result would still be correct. However, if the instruction depends on the current contents of the memory, such as xor, then the end result will likely be incorrect.
For example, imagine that a certain variable stored in memory at 0x1000c has 64-bit value 0xb1b0afaeadacabaa (little-endian), and we’re executing an xor on this region of memory (whose address is stored in rax) with 0xaaaaaaaaaaaaaaaa:
mov rbx,0xaaaaaaaaaaaaaaaa xor qword ptr [rax],rbx
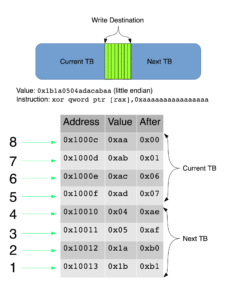
The first four bytes of the variable are located in the current TB, and the last four bytes are located in the next TB. The first four one-byte XORs, starting at the end of the stored variable, will succeed, and the resulting bytes will be stored in memory (0x1b, 0x1a, 0x05, and 0x04 respectively). The fifth xor, at 0x1000f, will fail since the destination TB is write-protected.
QEMU will then go through the unprotect process, and restore the CPU state to before the XOR. It then re-executes the XOR using the current state of memory, which includes the four previously XORed bytes. At this point, you may see how these conditions come together to result in an incorrect value. The last four bytes are XORed again, essentially negating the original XOR (a ^ b ^ b = a). Thus, while we expect 0xb1b0afaeadacabaa ^ 0xaaaaaaaaaaaaaaaa = 0x1b1a050407060100, we actually get 0xb1b0afaeadacabaa ^ 0xaaaaaaaaaaaaaaaa = 0xb1b0afae07060100.
Windows PatchGuard includes similar XORs in its decryption/encryption code, and the incorrect XOR results eventually spiral into a fatal stop with the DRIVER_IRQL_NOT_LESS_OR_EQUAL bug check.
So what’s the fix?
The fix was essentially as simple as reversing the single-byte write loop:
for (i = 0; i < DATA_SIZE; ++i) {
/* Little-endian extract. */
uint8_t val8 = val >> (i * 8);
/* Note the adjustment at the beginning of the function.
Undo that for the recursion. */
glue(helper_ret_stb, MMUSUFFIX)(env, addr + i, val8,
oi, retaddr + GETPC_ADJ);
}
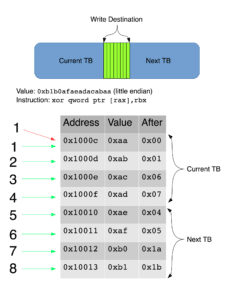
In addition to this simple fix, we also had to ensure that if the second TB didn’t have an entry in QEMU’s Translation Lookaside Buffer (TLB), then an entry for it is added. QEMU’s TLB is a mapping of guest virtual memory addresses to host virtual memory addresses. If the second TB does not have a TLB entry, it’s possible that during one of the four one-byte writes to the first page, the first page might evict the second page from memory before its writes occur, because QEMU would not necessarily know they are adjacent in guest memory. Since the TBs are adjacent, their TLB entries would also be adjacent, and QEMU knows not to flush TBs which are adjacent in the TLB. We didn’t have to deal with this before, because the second page couldn’t evict the first page, and the second page was being written to before the first.
With the patch applied, we are able to successfully boot and use Windows 7 and Windows 10 in QEMU emulated mode. Making the loop do the one-byte writes in the forward direction means that the the first byte QEMU tries to write will be in the current TB, and QEMU will immediately go through the unprotect process without writing any bytes to memory. The second write attempt will complete successfully and we’ll get the desired result, as shown in Figure 5.
We pushed this patch upstream, and the full patch is available at git.qemu.org.
Credit for discovering and diagnosing the original QEMU bug goes to Patrick Hulin. All code, diagrams, and explanations are original content unless otherwise noted.



