
Challenge Accepted
The Unity Obstacle Tower Challenge is a first-of-its-kind artificial intelligence challenge designed to test the capabilities of intelligent agents, accelerating AI research and development. The novel idea behind the challenge is testing the vision, control, planning, and generalization abilities of AI agents through a dynamic platforming game.
Challenging Challenges
To create a successful agent, reinforcement learning is necessary to adopt a policy that can be repeated to conquer any level the game can generate. Doing so is not a trivial task, and requires a good framework to develop models that can understand the problem space. This blog walks through my experience participating in this challenge, and highlights the pain points I encountered. I also share my recommendations on creating a positive user experience for future challenges.
An Artificial Intelligence Agent (AI Agent, or simply agent) is an autonomous machine entity which acts on an environment to achieve goals, utilizing sensors to gather information about its environment and react accordingly.
What is Reinforcement Learning
Reinforcement Learning (RL) can create an agent given an environment and actions to perform. The agent is rewarded for good actions and learns an optimal policy to get the best reward over many iterations. This allows for autonomous agents to push beyond human capabilities, like beating the best Go player in the world or defeating world champion video game teams. Agents will also be able to do things in the physical world like mass deliver packages with drones flying from a mothership (ok that one is currently fake, but this one is quite real, as is this one). To get involved with RL, I sought out a challenge that would provide a framework to test out different techniques. The Unity Obstacle Tower Challenge was presented as a robust playground to test out varying ways to train an agent. The description from the site read…
The Obstacle Tower is a procedurally generated environment consisting of an endless number of floors to be solved by a learning agent. The Obstacle Tower Challenge combines platforming-style gameplay with puzzles and planning problems, all in a tower with an endless number of floors for agents to learn to solve.
This was my first RL competition, so I was eager to get started.
Getting Started
To begin, I was directed to their GitHub repo to download starter code. This was my general workflow
-
git clone [email protected]:Unity-Technologies/obstacle-tower-challenge.git
-
pip install -r requirements.txt
- Some library doesn’t exist, search Stack Overflow for what to install
-
apt-get upgrade apt-get install library
- Repeat 2-4 until install competes
The first pain point was finding certain libraries, it was not an “out of the box” setup experience. There are tools to mitigate these issues such as Docker, which encapsulates the entire development environment into a single package. At the very least listing any prerequisites, or having a setup script would have been useful for a seamless onboarding experience.
In any case, after the environment was properly configured, the next step was to actually run an agent. The organizers provided a baseline agent that would simply make random moves. This was good from a smoke test point of view, as I was able to see how the agent worked and interacted with the environment. However, this agent will never pass floor 0, and this is where the reinforcement learning aspect comes in.
To begin the organizers recommend using an agent they trained in their research paper. They also recommended using Dopamine a research framework for fast prototyping of reinforcement learning algorithms.
The next pain point came while learning to train the agent. The instructions provided explained how to begin training in a cloud environment. For the training to be worthwhile, costly GPU instances would need to be used—up to 30 dollars a day. With no path provided for local training, it was up to the contestants to figure out how to start training on a budget.
As I personally have considerable experience debugging system issues, I was eventually able to set up a suitable training environment locally, utilizing my GPU, but doing so took time away from what I really wanted to invest in, the actual reinforcement learning.
(Feedback for potential challenge creators: onboarding should have considerably less friction for new participants to encourage a higher engagement rate—I was able to work through setup woes, others might not bother.)
Let the Training Commence
Training in reinforcement learning isn’t about labeled data or creating if statements for each use case, it revolves around the agent attempting a task (in this case, playing the game) millions of times to learn the best strategy to earn the optimal reward.
In the obstacle tower, a reward score of 1 is given for completing each floor and 0.1 for passing through a door. For the agent to progress from one level to the next, it must learn based on the pixels displayed on the screen which action to take. The agent has a total of 54 possible moves it can perform, and the goal of the agent is to determine what pixels correlate with the best scoring actions. Because the agent gets a reward of 0.1 each time it passes through a door, it will learn over time to prioritize finding door pixels and moving towards them.

The code to run the agent was provided from the challenge, but it very basic, as it simply performs actions until a terminal state is reached. We have more control over the hyperparameters which are parameters controlling how the agent learns, and how long we want to train the model.
Training Code | Hyperparameters
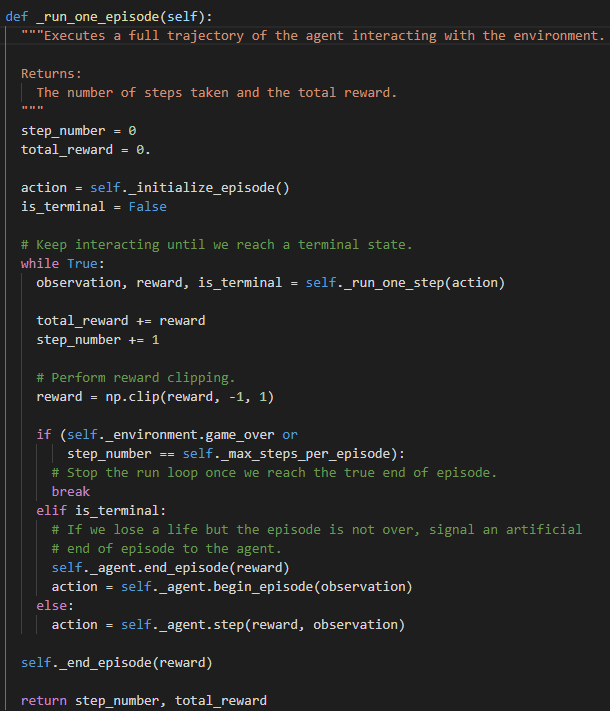
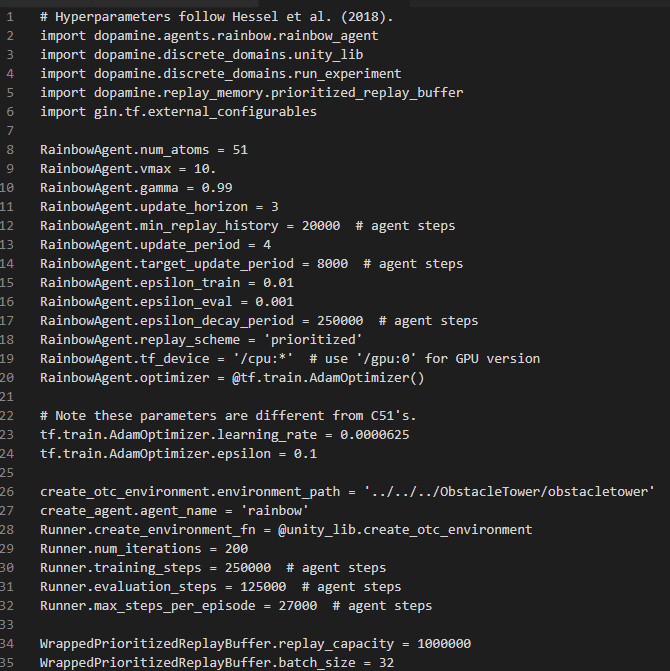
Training Code: https://github.com/google/dopamine/blob/master/dopamine/discrete_domains/run_experiment.py#L272
The organizers did a great job by providing code allowing the training process to begin seamlessly.
python -um dopamine.discrete_domains.train --base_dir=D:obstowercheckpoints --gin_files=rainbow_otc.gin
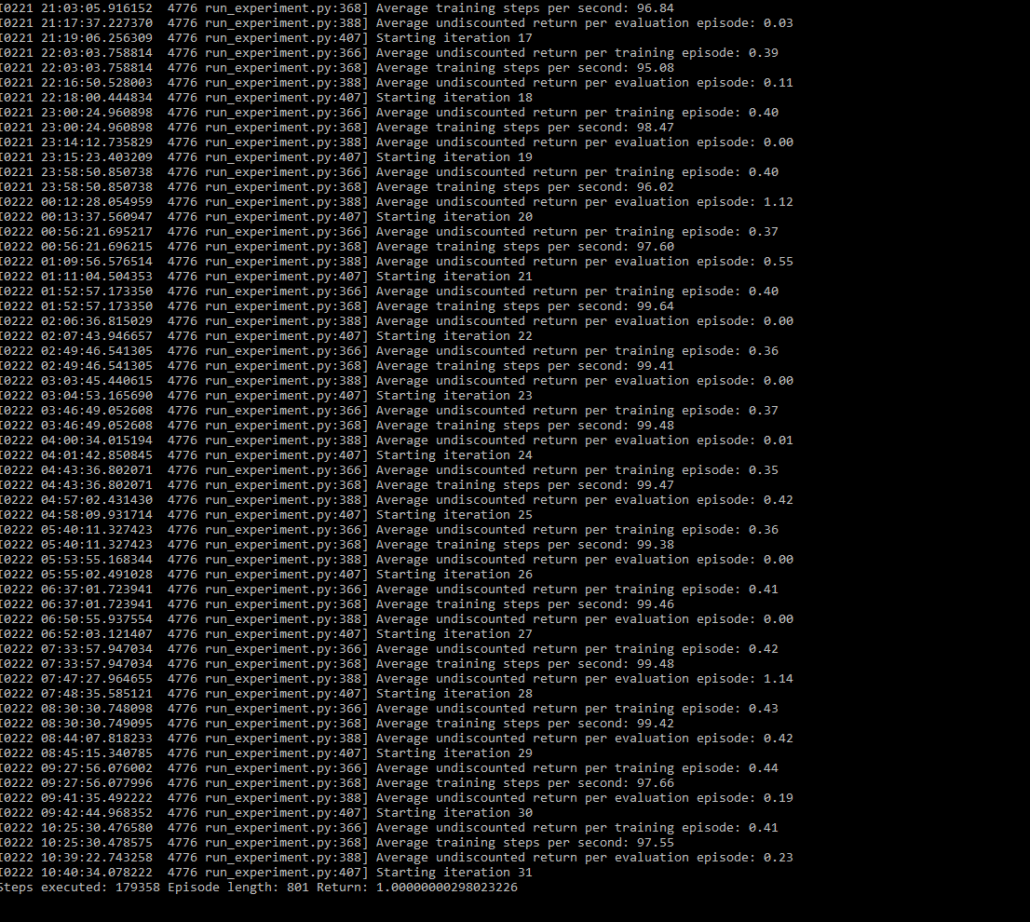
The training works by playing the game in a tiny 84×84 pixel window with a black background to speed up gameplay. 90 actions are taken per second, with an average of 5000 steps in each episode.
The training phase consists of 25,000 episodes evaluated 12,500 times, run 200 times for a total of 7,500,000 episodes of gameplay. This setup provides plenty of opportunities for the agent to adopt a policy that can adapt to a randomly generated level. The training code also checkpoints the model every hour to save progress, in case of any type of system error. There were no pain points in the section, the organizers did a great job in providing easy to use code to begin the training phrase.
After 4 days of training my agent was able to reach level 5 consistently with an average reward of 6.7. This aligns with results from their paper, so I was eager to get the agent evaluated on their server and get on the leaderboard.
Untrained Agent | Trained Agent


To have a fair evaluation, they required a Docker image embedded with your agent built with the repo2docker tool. This tool attempts to create a Docker image from your repo. Once the image is created, they launch their own environment for the agent.
The instructions were clear, and I was able to run their evaluation process locally. Unfortunately, things took a turn for the worse once my image was on their server.
Evaluation Woes
The first issue was the images were massive. My image was 22GB, while my repo was only 9GB. The repo2docker tool had a bug (or feature?) that doubled the size of the Docker image which quickly caused their evaluation server to run out of space.
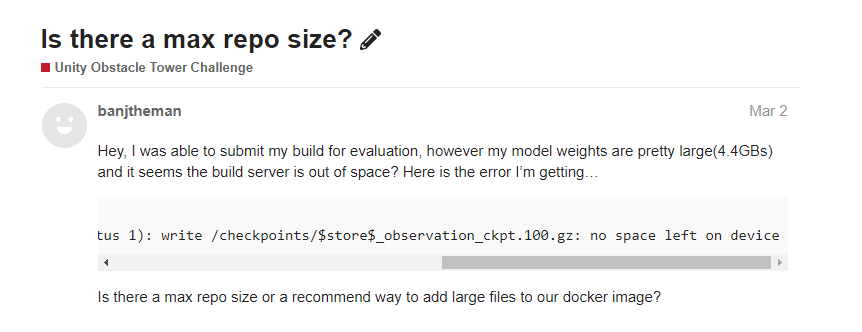
After other users started commenting on my post it was apparent something was wrong on the back end, and after much discussion, it was determined the docker run process not adding the –rm flag, causing many idle layers to persist after each failed run, rapidly consuming disk space.
(Another note for event organizers, apparently the base case wasn’t fully tested, putting the debugging on the contestants. It’s never possible to test every edge case, but the base case in provided documentation must be well tested, as a majority of users will be following that for their first submission—a truism in production environments as well.)
The next hurdle proved to be even more daunting, as it wasn’t a simple flag issue. Every run I submitted stalled for the duration of the timeout_wait parameter. First I thought the default 30 seconds was too low for their machines, so I increased to 300, then 600, then 30,000, each time with the same failure.
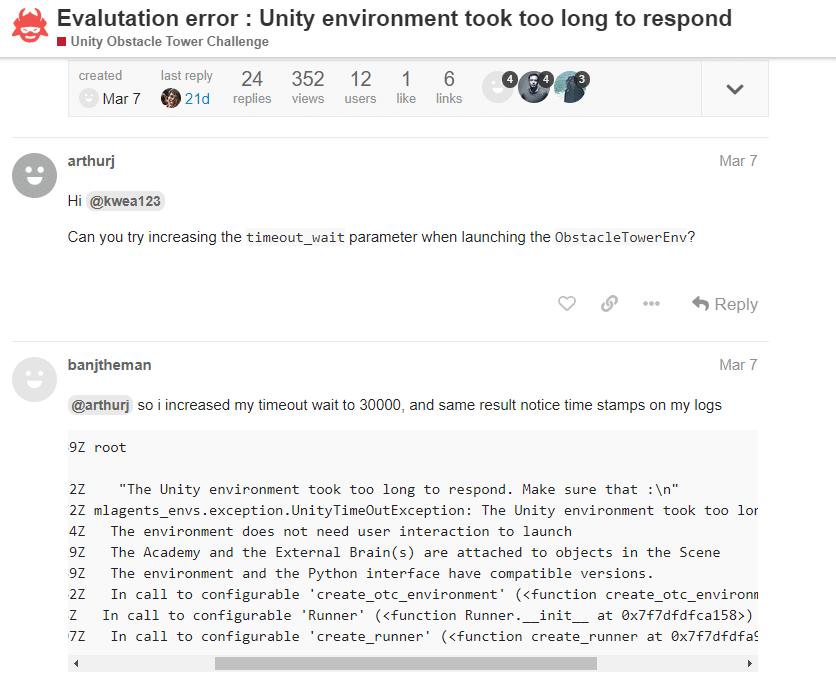
Puzzled by the situation, I even blurted out my favorite line as young developer…
╮ (. ❛ ᴗ ❛.) ╭ It works on my machine!
Frustrated, I submitted many runs with print statements embedded to see if I could glean anything useful from the server. To my unpleasant surprise, I achieved the worst possible outcome: the submission worked sometimes and then failed other times. This non-determinism made me wonder if I should even continue with the challenge. But then another contestant in the same boat found a clever way to get the test to start each time by deferring imports.
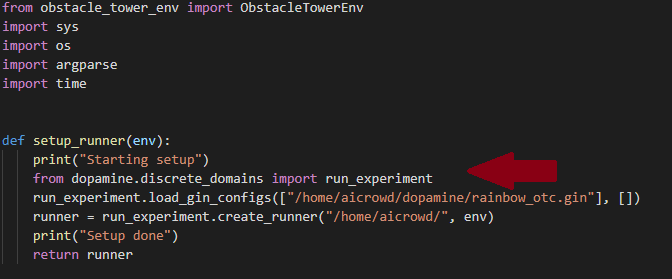
If the agent image took more than 5 seconds to start due to loading a bunch of python libraries, the test never began. By only importing libraries when necessary, the agent image was able to connect to the game server image within the set threshold and begin the test.
This goes back to the issue of not testing the base case. The submission process wasn’t tested with a trained agent, using the default code they provided. These kinds of roadblocks are easily avoided by doing a dry run of your submission process.
Unfortunately, I wasn’t out of the woods just yet.
To control the size of repos, the organizers added git-lfs to their GitLab server and if you have ever used git-lfs before, you understand it is a pain to set up. Converting a regular repo to lfs was a nonstarter due to the number of git commands necessary, so I wiped my initial repo and started from scratch. The new repo also provided me an opportunity to purge unnecessary files bloating the image. For example, each training run created a replay buffer that could reach sizes as large as 4GB, data entirely unnecessary for the evaluation.
rm -rf .git git init git remote add YOUR_URL git lfs install git lfs track big_file git add . git commit -am “initial commit” git tag -am “test” tag git push -u origin master tag
Starting from scratch made it easy to push my repo for evaluation, but problems still arose..
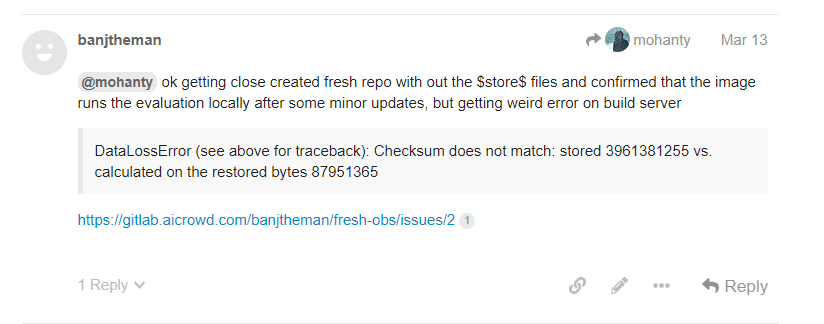
The server was not correctly downloading my model file, so when the evaluation began, there was no model for my agent to load. I suggested to the organizers they could explicitly call git lfs pull in their build process to grab the files, because their current methodology was only grabbing the pointers to the file, and not actually downloading any content.
This was easily the worst part of the challenge because of how brittle and untested the submission process was. All the tropes about bad development practices were on display during this process. From not testing the base use case, to introducing new features that broke the previous workflow. For anyone wanting to create a similar challenge, make sure the default setup is smooth and tested!
Now that the submission process was fixed, the challenge could begin.
Takeaways
Participating in this challenge, gave me 3 clear takeaways needed to ensure a positive contestant experience.
- Easy Onboarding
- Clear Development Workflow
- Simple Submission Process
I should also note that despite the issues I encountered, the organizers were active in the event forums, as well as fixing issues raised by other contestants. Communication goes a long way.
Easy Onboarding
This is necessary to ensure a low bounce rate, so people who start the challenge won’t leave due to difficulties following the provided directions. This contest had difficult onboarding due to unclear prerequisites for running the software, and no directions for training in a local environment.
Clear Development Workflow
Without this, contestants won’t know how the challenge should function. In this case, the organizers did a great job of providing code to display the progress of training runs, and an easy to use framework matching the workflow laid out in their research paper.
Simple Submission Process
This is vital so contestants can validate their work. Providing a clear and functioning baseline process gives contestants more time to refine their agents, without worrying if they can evaluate their progress. In this case, it unfortunately wasn’t so simple, as the submission process had a fair few speed bumps.
What’s Next
Hopefully my experience going through this challenge can shed some light on what is necessary to run successful events like this, and hackathons, workshops, or other type of computing challenges.
While I gained some unique debugging experience testing the evaluation server in production, I was disappointed I couldn’t test more RL techniques due to issues with submission. Luckily, they are giving away GCP credits for Round 2 of their challenge, giving me another opportunity to explore RL techniques for teaching an agent to conquer the tower. Here are some techniques I am interested in implementing for my agent.
https://arxiv.org/abs/1703.01161 – FeUdal Networks for Hierarchical Reinforcement Learning
https://arxiv.org/abs/1705.05363 – Curiosity-driven Exploration by Self-supervised Prediction
https://arxiv.org/abs/1703.03400 – Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks



