Background
In late August of 2017, I had the pleasure of joining the team here at Two Six Labs as a Research Intern, with a fair amount of programming experience in the JavaScript and Python ecosystems, but very little formal CS education or past collaborative experiences under my belt.
With that in mind, my time at Two Six Labs has taught many valuable (but humbling) lessons. The most consistent lesson is that of never-ending education; I had, and still have, a great deal to learn. With my one-year mark now in the rearview mirror, this is as good a time as any to reflect on my growth.
In an effort to avoid rambling about endless ideas and lessons, this discussion will be kept in the practical context of the first “full system” I had the opportunity to develop on this project. The practical context in this scenario comprises a data ETL (extract, transform, load) pipeline, written in Java, using Spring Integration.
This pipeline takes real world event data from the GDELT (Global Database of Events, Language, and Tone) Global Knowledge Graph[1], maps it to our project’s OWL[2] ontologies, and inserts the resulting data into Virtuoso[3], our triple store database.
As our team’s position on this project requires extensive knowledge of triple store scaling, we built the pipeline to generate substantial amounts of data to fully test its limits. In the process of testing, we discovered bugs and limitations within Virtuoso, while developing a richer understanding of its underlying components and capabilities. My work on this ETL pipeline, and the lessons contained within, can be broken down into the three pieces of ETL: extraction, transformation, and loading.
Extract
The first step in any ETL pipeline is extraction. In this case, parsing the GDELT GKG (Global Knowledge Graph) datasets into meaningful RDF (Resource Description Framework)[4] triples (more on “meaningful” later).
The GKG is a vast dataset which pulls from a large collection of news sources, encompassing a variety of events (e.g. criminal or political actions) with substantial context (such as location, actors, counts). The raw data is contained within a surprisingly unconventional CSV with an accompanying fifteen-page codebook[5].
By “unconventional”, I mean that this “CSV” utilizes field delimiters ranging from expected tabs and commas, to semicolons, colons, pound signs and even pipe characters. Once each tab-delimited section has been separated, you end up with fields such as V2.1COUNTS. Take this excerpt for example:
WOUND#4#soldiers#1#Afghanistan#AF#AF#33#65#AF#246;KILL#1##1#Afghanistan#AF#AF#33#65#AF#1000;
The line above denotes two blocks separated by a semicolon (“;”), with each sub-field identified by a hash symbol (“#”). This data would be useless without a descriptive codebook specifying each delimiter and field. Luckily, we had one readily available. After some data mangling, we ended up with a more useful representation of the data in the form of two Java objects:
GkgCountV2{
countType='WOUND',
count=4,
objectType='soldiers',
location=GkgLocation{
type=1,
fullName='Afghanistan',
countryCode='AF'
adm1Code='AF',
latitude=33.0,
longitude=65.0,
featureID='AF'
},
offset=246
}
GkgCountV2{
countType='KILL',
count=1,
objectType='',
location=GkgLocation{
type=1,
fullName='Afghanistan',
countryCode='AF',
adm1Code='AF',
latitude=33.0,
longitude=65.0,
featureID='AF'
},
offset=1000
}
Abstracting the implementation of this translation would be trivial if each field didn’t exploit unique values and delimiters. Instead of semicolons and pound symbols, other fields, such as V2GCAM, use comma-delimited (“,”) blocks with colon-delimited (“:”) key/value pairs, and fields like V2.1QUOTATIONS stray even further, utilizing pound-delimited (“#”) blocks with pipe-delimited (“|”) fields.
As I read the codebook and researched CSV parsing libraries, it was clear that an existing solution wouldn’t cut it. Taking to the creation of a custom GKG “CSV” parser, I made my first mistake: not properly employing Java types.
As mentioned earlier, I come from a JS and Python background, neither of which are typed languages. This project, however, was being written in Java, a heavily object-oriented and strictly typed language (ignoring type inference in the recently released Java 10). This led to the first iteration of my parser using maps, lists, and nested combinations of both to store the data.
The variety of types in the GKG meant I often defaulted to using a generic Object in these list and map structures. Because of this, when it came time to use the parsed data, I quickly realized the error of my ways. I had to “type cast”, or manually tell Java which type each object was just to retrieve an item in a list or value in a map.
It meant writing this mess:
String locationName = (String) ((Map) ((List) ((Map) data.get(0)).get("countsV1")).get(0)).get("locationFullName");
to simply access a value.
This was far from ideal and a more preferred solution had to be sought. After speaking with our resident Java and all things software engineering expert, Karl, I took the more object-oriented approach of creating classes for each nested data type. Not only was the data syntactically easier to work with, but each field was mapped to the exact type of data it contained. Accessing the location in which a count took place now looked like this:
String locationName = data.getRows().get(0).getCountsV1().get(0).getLocation().getFullName();
Not only is this shorter and easier to read, it is ferociously faster to compose with code autocompletion on hand.
Despite having developed all sorts of applications over the years, a seemingly trivial and amateur mistake set off a series of lessons. While it was a one-time mistake, it has greatly influenced all work I’ve done since its occurrence. In fact, I’ve come to appreciate strict typing and constant awareness of the exact data structure each component accepts and returns, to the point that I have gone out of my way to specify types in all my Python projects since. And when it comes to JavaScript, TypeScript has never before appeared so alluring.
Transform
Having learned my lesson in object-oriented programming, I moved onto transforming the data to align with our project based ontologies. An ontology, for those as unfamiliar as I was, is a model describing the object types and individuals in a domain, and the relationships between them.
For instance, if I wanted to store data from Hollywood articles relating to Steve McQueen, I would need a way to differentiate between Steve McQueen, the coolest actor of the 60s, and Steve McQueen, the modern Oscar winning director. To create this distinction, I could uniquely identify each Steve McQueen within an ontology. Using an IRI (as dictated by OWL), I would create the identifiers, “http://my.ontology#SteveMcQueenActor” and “http://my.ontology#SteveMcQueenDirector”, to refer to each individual in the data.
Continuing with the previous V2.1COUNTS scenario, this excerpt:
WOUND#4#soldiers#1#Afghanistan#AF#AF#33#65#AF#246;
Would translate to this RDF:
gkg-event:20150218230000-13-1 rdf:type event:Wounding ;
general:located_at gkg:Afghanistan ;
event:has_affected_actor gkg-actor:20150218230000-13-1 .
gkg-actor:20150218230000-13-1 rdf:type actor:GroupOfPersons ;
general:position_or_role "soldiers" ;
general:count 4 .
gkg-location:Afghanistan rdf:type general:PhysicalLocation ;
actor:iso_code_3166-2 "AF".
general:canonical_label "Afghanistan" ;
general:latitude 33.0 ;
general:longitude 65.0 .
This RDF fragment describes gkg-event:20150218230000-13-1 as a wounding event located in Afghanistan with a group of 4 soldiers affected. Furthermore, Afghanistan is described as a location with an ISO code, label, latitude and longitude. The gkg-event: prefix, along with all other prefixes preceding a colon, are simply a notation for defining an XML namespace (to avoid naming conflicts across ontologies).
The most common prefix, “rdf”, equates to http://www.w3.org/1999/02/22-rdf-syntax-ns#. Note that we could have opted to use the geonames database instead of defining our own Afghanistan individual. For illustration purposes, however, constructing our own represents the GKG data more thoroughly.
A fair amount of information can be garnered from a terse 50-character snippet of a single field. However, if the contextual properties are taken into account, a more complete picture begins to form. Using this additional information from the GDELT record, the following triples can be added:
article:20150218230000-13 rdf:type data-prov:Document, cco:Web_Page ;
data-prov:online_source "http://www.washingtonpost.com/news/checkpoint/wp/2015/02/18/army-rangers-get-top-valor-awards-for-heroism-on-deadly-day-in-afghanistan/" ;
data-prov:time_retrieved "2015-02-18T23:00:00"^^xsd:dateTime ;
data-prov:sourced_from gkg-record:20150218230000-13.
gkg-record:20150218230000-13 rdf:type data-prov:TabularReference ;
data-prov:line_number 13 .
gkg-event:20150218230000-13-1 data-prov:sourced_from article:20150218230000-13 ;
data-prov:char_offset 246 ;
general:latest_possible_end_time "2015-02-18T23:00:00"^^xsd:dateTime .
As may be gleaned through the descriptive properties, this RDF supplements the information above with the V2.1DATE and V2DOCUMENTIDENTIFIER fields. This auxiliary knowledge provides us with an event source and associated time. For instance, the wounding event now defines an explicit source of article:20150218230000-13, which itself is sourced from the GDELT CSV at line 13 (gkg-record:20150218230000-13). Using the data-prov:character_offset property, we can follow the chain of provenance through to the web page and exact point in the text where the information was sourced:
“…mortally wounding four soldiers and catastrophically injuring several others.”
In actuality, a “mortal wounding” would imply death. Given this information, we could add the more precise event type of MurderOrHomicide. However, the original level of accuracy is adequate for our use case. Although seemingly meaningless at first glance, through proper identification and transformation, this data has become usable not only quantitatively, but qualitatively as well.
While learning exactly what an ontology is and how to go about mapping the extracted GKG data to our project ontology, I discovered the utility of truly understanding your data. Instead of simply slapping values on fields, actually breaking down the data, looking for patterns, and mapping to useful identifiers make the data vastly more practical for real world use cases.
In short, data isn’t simply the information that gets passed through the application, it’s useful and revealing in and of itself. I’d venture to say you could create an entire field of study around it ;). This may be common knowledge to any experienced data scientist, but as my first venture into this territory, it was new, exciting, and revealed the extent of learning I still have to experience within the data science field.
Load
After the basic pipeline for extracting and transforming the data was in place, I was tasked with loading said data into Virtuoso, our triplestore database for this project. This task didn’t go so smoothly the first few tries…
The insert rate of the first run started out slow; 400 individual inserts per second slow. Seeing this, I realized something had to be horribly wrong with the code. After my initial investigation yielded no results, I once again consulted our New Jersey software development connoisseur, Karl. This time, Karl had a look at the issue and promptly recommended using Visual VM to diagnose the problem. So I fired up Visual VM and Karl showed me around. The CPU sampler is what I needed for this task.

After starting the ETL pipeline, Visual VM allowed me to take a sample of the running threads and see exactly which function was occupying the largest amount of CPU cycles. In this scenario, loading my statements using RDF4J was creating a new connection to Virtuoso for each and every insert. Enlightened to the whereabouts of the issue, I was able to locate and examine the offending code directly.
Consequently, a change was put in place to reuse the same connection with each insert via a pooled connection to the DB. This modification dramatically increased the insert rate from roughly 400 to 5,000 statements per second.
But the optimization wasn’t finished there. Each RDF statement was still being inserted into the database as an inefficient individual operation. To remedy this, I incorporated an aggregator provided by Spring Integration. The code looked something like this:
IntegrationFlows.from(statements)
.aggregate(a -> a.releaseStrategy(g -> g.size() == 200)
.expireGroupsUponCompletion(true)
This configuration instructs the aggregator to hold statements in a queue until the it contains 200 statements, then to pass all the queued statements down the pipeline for a bulk insert into Virtuoso. Rinse and repeat. Simple enough, right? Well, as expected, initiating the pipeline with my fancy new aggregator revealed a dramatically increased ingest rate of 15K statements / second.
This worked great, for the five minutes before it slowed down to a crawl. As I began debugging in Visual VM, I noticed the memory steadily increasing over time, to the point where garbage collection would continually trigger and nearly grind the pipeline to a halt.
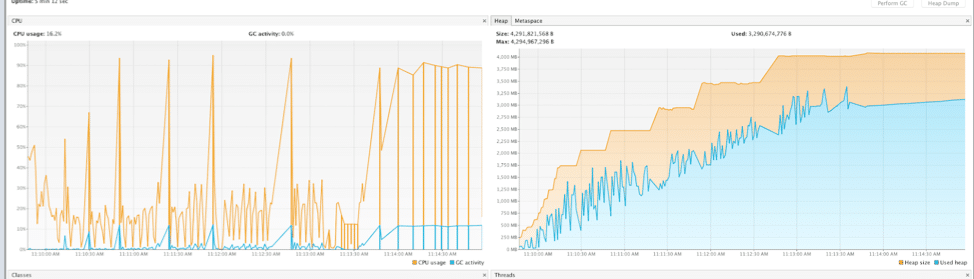
What could trigger such a catastrophic leak? Taking memory samples in Visual VM revealed that NodeHash arrays were the culprit, but what piece of code could be generating all these objects? Much furious googling, stack overflowing, and Spring Integration example searching later, I still wasn’t quite sure why memory was filling up with these objects. So what was left to try? Selling my soul and using a debugger.
Once again I’ll say that I come from a Python/JavaScript background, and not very long ago thought that using a debugger was only to deal with language shortcomings, and that an entire IDE (Integrated Development Environment) shouldn’t be necessary. This was one of the situations that would change my point of view.
I placed a few breakpoints around the code and began debugging. For the first couple tries, the code appeared to be operating properly. But after a bit more time, a few strategically placed breakpoints, and taking advantage of IntelliJ’s[6] conditional breakpoints, I was able to nail down the issue.
IntegrationFlows.from(statements)
.aggregate(a -> a.releaseStrategy(g -> g.size() == 200)
.expireGroupsUponCompletion(true)
.correlationStrategy(message -> message.getPayload().getClass())
The fix in this situation is above. I had been taking advantage of Spring IntegrationFlow’s “split” functionality previously in the pipeline, which assigns “correlation IDs” to every group of messages it processes.
However, these “correlation IDs” are random and unique for each group, and there was no guarantee these groups would be exactly 200 messages in size (in fact, there is good reason for them not to be).
When I instructed the aggregator to group these messages until 200 were queued, the aggregator would group them by correlation ID. This led to a group of say, 250 messages, with the same correlation ID, leaving a group of 50 behind. These 50 leftover messages would never reach the 200 count quota necessary to flow through the pipeline.
While the pipeline was running, incomplete message groups piled up, quickly filling memory to the brim. To fix the issue, the correlation strategy had to be explicitly instructed to group message by class instead of correlationID, as can be seen above.
This experience cemented my respect for using a debugger. Now, even when going back to Python or JavaScript, I always have a debugger handy to save time and aggravation.
Conclusion
So what have I learned? Well, in my time here at Two Six Labs, I’ve learned a bit about object-oriented programming and where to create types. The qualities of data itself and its ever-increasing usefulness have been continuously revealed throughout this project. I’ve learned new ways of debugging code via the use of a profiler. And finally, I’ve embraced using a fully integrated development environment and symbolic debugger.
Along the way, I’ve also learned various lessons about working in a team. The most important, I reckon, is how each individual’s skills and talents are especially invaluable when they are shared freely and effectively with others. In my case, I have Karl to thank for many of these lessons and many more not listed here. Of course, this post wouldn’t have happened without Mike Orr’s encouragement to share my experiences, so a tremendous thank you must be made there as well.
My hope is that in some way or another, you have been enlightened through my encounters with these lessons. Since my time spent creating this ETL pipeline, I’ve had the opportunity to work on many other enriching problems and projects that hold potential for a more technically in-depth review. As for the future, I am optimistically looking forward to the challenges, experiences, and lessons here at Two Six Labs.
[1] https://blog.gdeltproject.org/gdelt-global-knowledge-graph/
[3] https://virtuoso.openlinksw.com/
[5] http://data.gdeltproject.org/documentation/GDELT-Global_Knowledge_Graph_Codebook-V2.1.pdf



