
In this blog post, I’ll walk through how I developed an automated system to create an AWS Services knowledge graph using Grakn.ai. I’ll explain how I built the knowledge graph and go over tools for extracting information from technical documents. By the end of the blog post, you will know what a knowledge graph is and how to create one using open source tools.
AWS re:MARS
In June 2019, I was able to attend the first AWS re:MARS conference out in Las Vegas. There were all sorts of cool robots, workshops, and entertainment options. The keynotes were also awe-inspiring and ranged from Robert Downey, Jr. launching a coalition to combat ocean plastic to a protestor interrupting Jeff Bezos’s keynote. During the keynote from Amazon CTO Werner Vogels, he highlighted how complex the AWS ecosystem is by contrasting AWS from 2006 to today.

AWS 2006 vs AWS Today
AWS started with 3 services in 2006 and has over 160 services today. It really got me thinking that I myself only use a handful of services such as EC2, S3, Lambda, and RDS. What about all these other 160? How are all these connected?
What is a Knowledge Graph?
On my quest to finding out how the services are connected, I came across a peculiar term: “Knowledge Graph”. A quick Google search tells us a knowledge graph is a product Google uses to power its search. On the other hand, Academia gives us many other answers…
All this fluff boils down to that knowledge graphs “encode relationships between objects”. Going back to our AWS example, we have lots of services, and some of them are connected by how we use them, like having a Lambda function pull from S3. Could we drive discover new knowledge about AWS services if we created a knowledge graph about them? Only one way to find out…
DataOps
To begin, I needed to create an ontology, which is basically a schema for what I’m trying to model. I also needed software to encapsulate the idea of a knowledge graph. Luckily, https://grakn.ai/ was built for this use case, and it had a Python API, so I was eager to get started. The ontology for this is simple: Service A can have a relationship with Service B if they are used together. In the diagram below, “Linkage” is this relationship between Services.
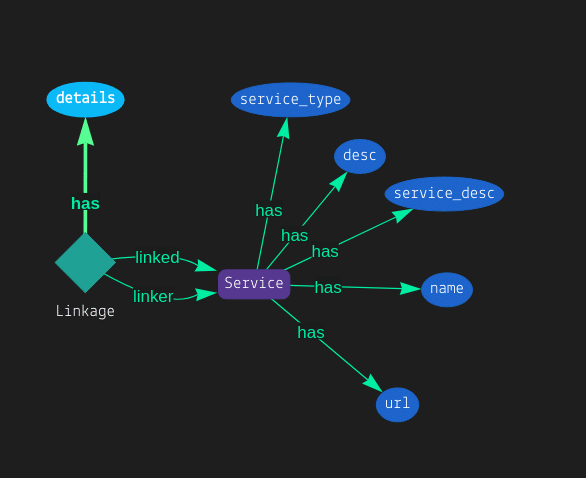
After the ontology is created, data can be inserted into the knowledge graph so we can unlock insights! Only there is one problem…where is this data? There’s no CSV file with AWS products on Kaggle or anything of the sort, so I ended up having to scrape together product data. https://aws.amazon.com/products/ listed all the products, so I did web scraping to collect them all using BeautifulSoup relatively easily.
#Get products
web_address = "https://aws.amazon.com/products/"
page = requests.get(web_address)
html = page.text
soup = BeautifulSoup(html, "html.parser")
cats = soup.findAll('div',{'class':'lb-item-wrapper'})
services_array = []
for cat in cats:
products = cat.findAll('div',{'class':'lb-content-item'})
for product in products:
service_object = {}
#service_type
service_object["service_type"] = cat.a.text.strip()
#url
service_object["url"] = "https://aws.amazon.com"+product.a["href"].split("/?")[0]
#desc
service_object["desc"] = product.a.span.text.strip()
#name
service_object["name"] = product.a.text.replace(product.a.span.text,"").strip()
services_array.append(service_object)
With the products in tow, I just needed a way to extract the relationships between each Product. Manually encoding them was not enough; I needed a “ground truth” source straight from AWS about how these products are utilized together. Thinking back to how I studied for the exams to gain knowledge about how services were connected, it dawned on me that AWS already provides a wealth of information on how all services are utilized together.
The Whitepapers
The AWS whitepapers are technical documents written by AWS on how they build solutions. These documents contained the “ground truth” that I was looking for. With over 200 whitepapers dating all the way back to 2010, I immediately began building a pipeline to download, convert, and extract knowledge from the whitepapers.
Downloading
Similar to the products, I used Selenium to extract metadata for each paper and wget to download the pdfs. Once downloaded, I used pdf2txt.py, which, as you can guess turns PDFs to text files. This allowed me to use Natural Language Processing (NLP) to extract relationships between entities.
NLP
The converted whitepapers proved to be messy as a text file with random special characters, line breaks, page numbers scattered throughout the document, and the title on every page. However, I utilized a pre-trained NLP model from spaCy and was able to extract meaningful sentences from each whitepaper.
{
"associationType": "PRODUCT",
"prep": "in",
"subject": "Amazon EMR",
"entity": "backed",
"sentence": "Build Amazon SageMaker notebooks backed by Spark in Amazon EMR.",
"snippet": "backed in Amazon EMR",
"adjectives": [
{
"subject": "Amazon EMR",
"adjectives": ""
}
],
"collectedTime": "2020-02-20 23:46:59.724696"
},
In this example, we have the sentence “Build Amazon SageMaker notebooks backed by Spark in Amazon EMR”. The subject is Amazon EMR, and Amazon SageMaker is in the sentence. This is how I defined a relationship. In our knowledge graph ontology, this is the “Linkage” relationship that we made. We can represent our data like…
{
"service1": "Amazon EMR",
"service2": "Amazon SageMaker",
"sentence": "Build Amazon SageMaker notebooks backed by Spark in Amazon EMR.",
"whitepaper_url": "https://d1.awsstatic.com/whitepapers/aws-power-ml-at-scale.pdf?did=wp_card&trk=wp_card",
"whitepaper_name": "Power Machine Learning at Scale",
"whitepaper_desc": "Best practices for machine learning workflows at scale on AWS.",
"whitepaper_topic": "Machine Learning and; AI",
"whitepaper_date": "May 2019"
}
Now that we have all the Products and Linkages, it’s time to load up the knowledge graph.
Loading Data into Grakn
While Grakn.ai has extensive docs, there were growing pains in using the API. The most notable ones are
- Spending a lot of time understanding their query language Graql
- Learning that “desc” is a keyword and you shouldn’t name an attribute that
- Special characters = bad
Here is a snippet of code that crafts the Graql query to be executed
def add_service(service):
url_string = service["url"].replace("https://","https_").replace("/","_").replace(".","_dot_")
graql_insert_query = 'insert $c isa Service, has name "' + str(service["name"]) + '"'
graql_insert_query += ', has service_desc "' + str(service["desc"]) + '"'
graql_insert_query += ', has url "' + str(url_string) + '"'
graql_insert_query += ', has service_type "' + str(service["service_type"]) + '"'
graql_insert_query += ";"
return graql_insert_query
def linked(linked_rel):
graql_insert_query = 'match $linked isa Service, has name "' + linked_rel["service1"] + '";'
graql_insert_query += ' $linker isa Service, has name "' + linked_rel["service2"] + '";'
graql_insert_query += (" insert $linkage(linked: $linked, linker: $linker) isa Linkage; " + "$linkage has details '" + str(linked_rel["details"]) +"'; ")
return graql_insert_query
.....
with session.transaction().write() as transaction:
graql_insert_query = add_service(service)
print("Executing Graql Query: " + graql_insert_query)
transaction.query(graql_insert_query)
transaction.commit()
After all the retrying and debugging, I finally got the script to insert everything and the result was….
Voilà! This crude extraction from the PDFs resulted in 3860 links between 189 services. Here’s a list of the top 10 linked services.
- Amazon S3 – 692
- Amazon EC2 – 377
- Amazon EMR – 250
- Amazon RDS – 234
- Amazon Redshift -148
- AWS Lambda – 147
- Amazon VPC – 137
- Amazon DynamoDB – 122
- Amazon Athena – 107
- Amazon CloudFront – 94
It’s no surprise S3 was most linked, followed by EC2. EMR was surprising to take 3rd spot and Lambda down in 6th. 59 services had no links such as AWS DeepComposer or Amazon Timestream. It could be that these services are too new or niche to be integrated with core AWS products.
What Can You Do with a Knowledge Graph?
Well, it’s cool we gained those insights, but the inevitable question is so what can you do with the knowledge graph? If you find out, please reach me on Twitter, @banjtheman.
Ha, but I was able to come up with one application…an automated quiz generator. Since we have all the products and thousand of sentences, I was able to create a program to make random multiple choice fill in the blank questions ripped straight from the whitepapers. The knowledge graph was useful in selecting answers that were “linked” to the correct answer instead of picking random services, to ensure test takers can differentiate similar services. Here is a snippet of the code I used to find related services utilizing the knowledge graph:
def query_grakn(answer):
grakn_query = 'match $common-service isa Service, has name $name; $service-a isa Service, has name "'+answer+'";(linked: $service-a, linker: $common-service) isa Linkage; get;'
return grakn_query
The query returns services that have a relationship to the answer. With the ability to know what services are related, it allows the multiple choices to be more constructed instead of wildly generating services that may not be relevant to the answer. Here is an example question with randomly generated answers, and one empowered by the knowledge graph.
The most common compute service used in IoT is ____________ , which allows actions to be invoked when telemetry data reaches AWS IoT Core or AWS IoT Greengrass. Randomly generated a: "Amazon DeepRacer" b: "Amazon Redshift" c: "Amazon Inferentia" d: "AWS Lambda" Knowledge graph generated a: "AWS Step Functions" b: "AWS CodeDeploy" c: "AWS Lambda" d: "Amazon VPC"
The knowledge graph generated answers are more aligned with the correct answer (pst… AWS Lambda). Whether or not this makes the quiz “better” is subjective of course, but AWS exams are notorious for throwing many similar answers together, and you have to use your expertise to fish out the one true answer. This quiz attempts to mimic that style, and it’s thanks to the knowledge graph that it can dynamically generate these types of quizzes.
You can take a quiz here.
Future Work
I’m sure the spaCy model missed some entities, but they provide a way to train your own entity model, and with all the samples I have it will be great to train and run a new model on the PDFs. Microsoft and Google also have products and whitepapers, and it will be great to do this exercise for both cloud vendors as well.



