
Bidding for Builds
This post covers the how of using EC2 spot instances for continuous integration (CI), and the why you want to do this.
Really, a whole post on that?
For a CI system to usable, it must fulfill specific needs.
- Builds must be (largely!) reproducible
- Providing access control
- Delivering logs
- Allowing build generation via multiple means
- Accurately allocating compute resources
- Allowing artifact archival
- Allow arbitrary command execution
If you think about these needs for a bit, a well-developed CI system begins to look a bit like a simplistic execution platform.
Such an execution platform was required for an internal Two Six Labs project. Retrofitting CI was a good way to meet that need, and this post covers the details.
The starting point – Gitlab CI
Gitlab tightly integrates the addressing of all CI system needs. Using it allows us to centralize user permissions across both source control and our “simplistic execution platform”. Gitlab CI also provides the ability to trigger jobs via webhooks, and passing environmental variables to jobs as arguments. When jobs are triggered, environmental variables are saved, checking the “permits jobs to be replicated” box.
Gitlab CI also supports, to varying degrees, a handful of “executors”. I say “executors” as the specific executor we use, Docker Machine, is more a poorly-supported provisioner than an executor.
Docker Machine
One of Docker Machine’s many features is handling most of the details involved in spinning up and tearing down EC2 Spot instances, such as setting maximum bid price.
Provided the commands you need to run can be executed within a Docker container, Docker Machine can serve as a decent provisioner, providing compute only as you need it.
Making Gitlab work well with Docker Machine
Spot instances are, as you may know, fantastically low-cost. They are low cost, because their availability both before and after provisioning is not guaranteed. Spot instance pricing changes with regional and zone demand, and provisioned spot instances can be terminated after a two minute warning.
Gitlab CI does not address spot instance termination. If a spot instance running a job is terminated, Gitlab CI eventually marks that job as failed. This is problematic because regardless of what you’re using it for, knowing if a task has failed or completed is too useful and too basic a feature to lose. The workaround to this issue we use the script check_termination.py.
Handling Terminations
check_termination.py is wrapped in a user-data.sh file and passed to the instance as Docker Machine provisions it. user-data.sh configures a cron job to run check-termination.py every thirty seconds, allowing it to cancel all jobs if the instance is marked for termination. There’s a bit more to this script, so I’m going to go through it function-by-function.
Imports
The interesting thing here is the docker package. This Docker library is unique in how high quality it is. I doubt there is any other Docker library, in any language, of such high quality.
#!/usr/bin/env python import docker import requests import os from sh import wall from sh import echo from pathlib import Path
Main
This script checks if any jobs are in need of termination and performs the termination if so.
def main():
if to_be_terminated():
terminate_jobs()
if __name__ == '__main__':
gitlab_api = “https://example.com/api/v4”
main()
Check Termination
This function determines if the instance is to be terminated and if that termination needs to be addressed.
One thing to note is that the IP being checked is present on all instances on AWS and AWS clones.
def to_be_terminated():
if not Path("/clean-exit-attempted").is_file():
try:
resp = requests.get('http://169.254.169.254/latest/meta-data/spot/termination-time')
resp.raise_for_status()
return True
except:
return False
else:
return False
Wall All
This function is mainly for debugging, using wall to broadcast messages to all ttys.
def wall_all(container, msg):
wall(echo(msg))
container.exec_run(f'sh -c "echo '{msg}' | wall"')
Terminate Jobs
This function has several roles. It first acquires the job ID of the Gitlab CI job on the runner, and then cancels that job so it is not marked as having failed. Lastly, it retries the job, allowing the job to complete without user intervention.
It also will run the script /exit_cleanly.sh if it exists, which is useful if your jobs are stateful in a way CI doesn’t quite support.
def terminate_jobs():
client = docker.from_env()
Path("/clean-exit-attempted").touch()
for container in client.containers.list(filters = {'status': 'running',}):
try:
jid = container.exec_run('sh -c "echo ${CI_JOB_ID?"NOJOB"}"')[1].decode('utf-8').strip('n')
pid = container.exec_run('sh -c "echo ${CI_PROJECT_ID?"NOJOB"}"')[1].decode('utf-8').strip('n')
if (pid != "NOJOB") and (jid != "NOJOB"):
job_container = container
container.exec_run('sh -c "/exit-cleanly.sh"')
except:
wall_all(job_container,f"Giving on on clean exit and restarting job {jid} of project {pid}.")
pass
kill_url = f"{gitlab_api}/projects/{pid}/jobs/{jid}/cancel"
retry_url = f"{gitlab_api}/projects/{pid}/jobs/{jid}/retry?scope[]=pending&scope[]=running"
auth_header = {'PRIVATE-TOKEN': os.environ.get('GITLAB_TOKEN')}
killed = False
tries = 20
while not killed and tries > 0:
try:
tries -= 1
resp = requests.post(kill_url, headers = auth_header)
#gitlab status code
print(resp.json()['id'])
killed = True
except:
wall_all(job_container,'Failed to cancel job, retrying.')
pass
if killed:
wall_all(job_container,"Cancellation successful.")
retried = False
tries = 20
while not retried and tries > 0:
try:
tries -= 1
resp = requests.post(retry_url, headers = auth_header)
#gitlab status code
print(resp.json()['id'])
retried = True
except:
wall_all(job_container,'Failed to restart job, retrying.')
pass
if retried:
wall_all(job_container, "Restarted job - That's all folks!!!.")
User Data
This user-data.sh file contains the check_termination.py. Docker Machine has AWS execute this script on instances once they are provisioned.
#!/bin/bash cat << "EOF" > /home/ubuntu/check_termination.py … EOF crontab << EOF GITLAB_TOKEN=gitlabtoken * * * * * python3.6 /home/ubuntu/check_termination.py EOF
Zombies?!?!
A problematic bug I had to workaround was Docker Machine abandoning provisioned instances, seemingly when it is rate-limited by AWS. The percentage of machines abandoned increase as the number of machines provisioned at once does. Fortunately, when this bug occurs, the instance in question is never tagged. As we only use Docker Machine to provision instances for CI, this allowed us to find and terminate instances meeting the criterion. The script we use is spot_sniper.py.
Spot Sniper
This script terminates abandoned spot instances. While this script is straightforward, this breakdown serves a vital purpose: preventing runaway AWS bills. Abandoned instances are not counted against the configured resource limits, allowing them to accumulate.
Imports
Some standard imports.
#!/usr/bin/env python3 import boto3 from pprint import pprint import toml import os import syslog
Main
This script looks for and terminates abandoned spot instances.
There is a bug somewhere between Docker Machine and Gitlab Runner that causes instances to be abandoned.
Instances that are abandoned by this error are identifiable by the lack of a name tag while having the docker-machine security group.
This script also terminates instances abandoned by min_bid_price.py as the instances that script provisions are configured to look abandoned.
def main():
regions = ['us-east-1', 'us-east-2']
for region in regions:
ec2 = boto3.resource('ec2', region_name = region, aws_access_key_id=os.environ['AWS_KEY'],aws_secret_access_key=os.environ['AWS_SECRET'])
all_ci_instances = set(ec2.instances.filter(Filters = [
{'Name': 'instance.group-name', 'Values': ['docker-machine']},
{'Name': 'instance-state-name', 'Values': ['running']},
]))
all_functional_ci_instances = set(ec2.instances.filter(Filters = [
{'Name': 'instance.group-name', 'Values': ['docker-machine']},
{'Name': 'instance-state-name', 'Values': ['running']},
{'Name': 'tag-key', 'Values': ['Name']},
]))
# This right here is how the bug somewhere between Docker Machine and Gitlab Runner expresses itself.
horde = all_ci_instances - all_functional_ci_instances
if len(horde) == 0:
syslog.syslog("spot_sniper.py - No abandoned spot instances.")
for zombie in horde:
kill_with_fire(zombie)
if __name__ == '__main__':
main()
Kill With Fire
This function terminates abandoned instances. It’s main purpose is to allow zombie instances to be killed with fire, instead of simply being terminated.
def kill_with_fire(zombie):
syslog.syslog(f"spot_sniper.py - Terminating zombie spot instance {zombie.id}.")
zombie.terminate()
Crontab
This cron runs every 3 minutes. It needs to be tuned to minimize waste without causing excessive rate-limiting.
*/3 * * * * python3.6 /root/gitlab-ci-ami/spot_sniper.py
Optimizing Instances Used
As spot instance prices vary across regions, zones in those regions, instance types and time; costs can be minimized by checking across those axes. We wrote the script min_bid_price.py to do this.
Min Bid Price
While min_bid_price.py was initially intended to be a script run by cron to select the cheapest combination of region, zone and instance type; we also needed to determine instance availability. We found that requesting a few spot instances, waiting a few seconds, and checking if those instances were available was an effective way to do this.
The following breakdown details the what and why of each component of min_bid_price.py.
Imports
There are a couple of interesting imports in this script:
#!/usr/bin/env python3 from sh import sed from sh import systemctl from functools import total_ordering
The sh package is a package that wraps binaries on $PATH, allowing them to be used in as pythonic a way as is possible without having to use a dedicated library.
total_ordering is an annotation that, provided an equivalence and a comparison operator are defined, will generate the not-explicitly-defined equivalence and comparison operators.
Instance Profile Class
instance_profile obtains, stores and simplifies the sorting of pricing info from AWS.
@total_ordering
class instance_profile:
def __init__(self, instance, region, zone):
self.instance = instance
self.region = region
self.zone = zone
self.price = None
def determine_price(self, client):
try:
resp = client.describe_spot_price_history(InstanceTypes=[self.instance],MaxResults=1,ProductDescriptions=['Linux/UNIX (Amazon VPC)'],AvailabilityZone= self.region + self.zone)
self.price = float(resp['SpotPriceHistory'][0]['SpotPrice'])
return True
except:
return False
def __eq__(self, other):
if self.price == other.price:
return True
else:
return False
def __gt__(self, other):
if self.price > other.price:
return True
else:
return False
def __str__(self):
if self.price is None:
return f"No price for {self.instance} {self.region}{self.zone}"
else:
return f"{self.instance} at {self.region}{self.zone} costing {self.price} at {datetime.datetime.now()}"
Main
There’s a fair amount going on here, so a few interruptions for the following function:
def main():
This code block specifies instances, regions and zones to be considered for use:
instances = ['m5.xlarge', 'm4.xlarge', 'c4.2xlarge', 'c5.2xlarge'] regions = ['us-east-1','us-east-2'] zones = ['a', 'b', 'c', 'd', 'e', 'f']
Here I specify the AMI to use in each region, as AMIs are not available across regions:
region_amis = {'us-east-1': 'ami-5bc0cf24', 'us-east-2': 'ami-3de9d358'}
The following code block specifies the criteria an instance_profile must meet to be usable. It specifies that an instance_profile must enable the provisioning of 3 instances via 3 separate spot instance requests in under 10 seconds when max bid price is 0.08 cents per hour:
max_bid = 0.08 test_instances = 3 wait_retries = 2
The following snippet assures the system configuration can be updated, before firing off AWS requests to find a suitable instance_profile and updating system configuration.
if safe_to_update_config():
inst_confs = get_price_list(instances,regions,zones)
for conf in inst_confs:
if spot_test(conf.region, conf.zone, region_amis[conf.region], conf.instance,
test_instances, max_bid, wait_retries):
if safe_to_update_config():
syslog.syslog(f"min_bid_price.py - Min Price: {conf}")
update_config(conf,region_amis)
break
else:
syslog.syslog(f"min_bid_price.py - Cannot update config as jobs are running.")
break
else:
syslog.syslog(f"min_bid_price.py - {conf} failed provisioning check.")
else:
syslog.syslog(f"min_bid_price.py - Cannot update config as jobs are running.")
if __name__ == '__main__':
main()
Update Config
The following block of code uses sed, via sh, to edit Gitlab Runners /etc/gitlab-runner/config.toml configuration file.
If you anticipate needing to use multiple instance types, use the toml package instead of sh and sed here.
def update_config(next_inst,region_amis):
sed("-i", f"s/amazonec2-zone=[a-f]/amazonec2-zone={next_inst.zone}/g", "/etc/gitlab-runner/config.toml")
sed("-i", f"s/amazonec2-ami=ami-[a-z0-9]*/amazonec2-ami={region_amis[next_inst.region]}/g", "/etc/gitlab-runner/config.toml")
sed("-i", f"s/amazonec2-instance-type=[a-z0-9]*.[a-z0-9]*/amazonec2-instance-type={next_inst.instance}/g", "/etc/gitlab-runner/config.toml")
systemctl("restart", "gitlab-runner")
syslog.syslog(f"min_bid_price.py - Moved CI to {next_inst}")
Get Price List
The following function creates a boto3 client for each region being considered, and uses those clients to create a price-sorted list of instance_profile objects.
def get_price_list(instances, regions, zones):
price_list = []
for region in regions:
client=boto3.client('ec2',region_name=region,aws_access_key_id=os.environ['AWS_KEY'],
aws_secret_access_key=os.environ['AWS_SECRET'])
for instance_type in instances:
for zone in zones:
price = instance_profile(instance_type, region, zone)
if price.determine_price(client):
price_list.append(price)
price_list.sort()
return price_list
Safe to Configure
This function determines if it is safe to update system configuration. It determines this by assuring that both:
- No CI jobs are running and,
- No non-zombie Docker Machine instances are running
def safe_to_update_config():
auth_header = {'PRIVATE-TOKEN': os.environ['GITLAB_TOKEN']}
try:
resp = requests.get('https://example.com/api/v4/runners/4/jobs?status=running', headers = auth_header)
resp.raise_for_status()
except:
syslog.syslog('min_bid_price.py - Cannot get runner status from example.com. Something up?')
return False
if len(resp.json()) != 0:
return False
else:
instances_running = "/root/.docker/machine/machines"
if os.listdir(instances_running):
return False
return True
Spot Test
This function tests instance_profile objects to determine their usability, by exploring if instances can be provisioned quickly enough for the instance_profile in question.
If you’re wondering why instance_profile is absent , it processes the components of instance_profile.
def spot_test(region, availability_zone, ami, instance_type, instances, max_bid, wait_retries):
client = boto3.client('ec2', region_name = region, aws_access_key_id=os.environ['AWS_KEY'],aws_secret_access_key=os.environ['AWS_SECRET'])
req_ids = spot_up(client, instances, max_bid, ami, availability_zone,
region, instance_type)
usable_config = check_type_in_az(client, wait_retries, req_ids)
spot_stop(client, req_ids)
spot_down(client, req_ids)
if usable_config:
syslog.syslog(f"min_bid_price.py - {region}{availability_zone} {instance_type} wins as it spins up {instances} instances in {wait_retries*5} seconds at max_bid {max_bid}.")
return True
else:
syslog.syslog(f"min_bid_price.py - {region}{availability_zone} {instance_type} loses as it fails to spins up {instances} instances in {wait_retries*5} seconds at max_bid {max_bid}.")
return False
Spot Up
This function requests the specified number of spot instances and returns a list of the IDs of those requests.
def spot_up(client, instances, max_bid, ami, availability_zone, region, instance_type):
responses = []
for i in range(instances):
responses.append(client.request_spot_instances(
LaunchSpecification={
'ImageId': ami,
'InstanceType': instance_type,
'Placement': {
'AvailabilityZone': region + availability_zone,
},
},
SpotPrice= str(max_bid),
Type='one-time',
InstanceInterruptionBehavior='terminate')
)
return [x["SpotInstanceRequests"][0]["SpotInstanceRequestId"] for x in responses]
Spot Stop
This function cancels outstanding spot instance requests. It can fail when the system is being rate limited by AWS. Requests not cancelled will be fulfilled and cleaned up by spot_sniper.py. This failure is permitted as it results in stderr being emailed via cron, letting us know to not slam the system with jobs for a couple minutes.
def spot_stop(client, req_ids):
cancellations = (client.cancel_spot_instance_requests(SpotInstanceRequestIds=[x])["CancelledSpotInstanceRequests"][0]["State"] == "cancelled" for x in req_ids)
while False in cancellations:
print(f"min_bid_price.py - Failed to cancel all spot requests, retrying")
time.sleep(5)
cancellations = (client.cancel_spot_instance_requests(SpotInstanceRequestIds=[x])["CancelledSpotInstanceRequests"][0]["State"] == "cancelled" for x in req_ids)
Spot Down
This function terminates provisioned spot instances. It can fail when the system is being rate limited by AWS, in which case spot_sniper.py will clean up the provisioned instances during its next pass.
def spot_down(client, req_ids):
instances = [client.describe_spot_instance_requests(SpotInstanceRequestIds = [x]) for x in req_ids]
terminate_ids = []
for x in instances:
try:
terminate_ids.append(x["SpotInstanceRequests"][0]["InstanceId"])
except KeyError:
pass
if len(terminate_ids) > 0:
client.terminate_instances(InstanceIds = terminate_ids)
Check Instance Type in AZ
This function checks the status of spot instance requests made every five seconds until either the specified number of retries are made, all requests are fulfilled, or one request will not be fulfilled.
def check_type_in_az(client, wait_retries, req_ids):
statuses = spot_req_status(client, req_ids)
while wait_retries > 0 and req_status_check(statuses) is None:
wait_retries -= 1
statuses = spot_req_status(client, req_ids)
time.sleep(5)
if req_status_check(statuses) is None:
return False
else:
return req_status_check(statuses)
Spot Request Status
This function returns a list of the statuses of spot requests made.
def spot_req_status(client, req_ids): return [client.describe_spot_instance_requests(SpotInstanceRequestIds=[x])["SpotInstanceRequests"][0]["Status"] for x in req_ids]
Request Status Check
This function reduces a list of spot requests to a boolean once their success can be determined, returning None if their success cannot be determined.
def req_status_check(statuses):
for x in statuses:
if (x["Code"] == "pending-evaluation") or (x["Code"] == "pending-fulfillment"):
return None
elif x["Code"] != "fulfilled":
syslog.syslog(f"Fail req_status: {x['Code']}")
return False
else:
pass
return True
Crontab
This crontab runs min_bid_price.py every 10 minutes.
The period of this cron needs to be tuned for your use case.
If it is too wide, it is less likely that system configuration will be updated when users are active.
If it is too narrow, the cost of determining instance availability will increase as instances are billed by the minute for their first minute.
*/10 * * * * python3.6 /root/gitlab-ci-ami/min_bid_price.py
Config, config, config…
AMI
As bandwidth costs on AWS can add up and Spot Instance usage is billed by the second (after the first minute), we pre-load a handful of images we use often into the AMI used by Docker Machine to provision instances.
Gitlab Runner Config
This is the config.toml we use for Gitlab Runner. Key points to note are the volume mounts it configures, and the max builds limitation. The volume mounts are configured to allow CI jobs to use volume mounts of their own. MaxBuilds being set to 1 prevents port conflicts from occurring and ensures that all jobs are run in a clean environment.
concurrent = 80 check_interval = 0 [[runners]] name = "alpine" limit = 80 url = "https://example.com/“ token = “XXXXX” executor = "docker+machine" output_limit = 16384
[runners.docker]
tls_verify = true image = “BUILD_IMAGE_TAG” privileged = true disable_cache = true shm_size = 0 volumes = [“/var/run/docker.sock:/var/run/docker.sock”,”/builds:/builds”,”/cache:/cache”]
[runners.cache]
[runners.machine]
MachineDriver = “amazonec2” MaxBuilds = 1 MachineName = “gitlab-docker-machine-%s” OffPeakIdleCount = 0 OffPeakIdleTime = 0 IdleCount = 0 IdleTime = 0 MachineOptions = [ “amazonec2-request-spot-instance=true”, “amazonec2-spot-price=0.080”, “amazonec2-access-key=XXXXX”, “amazonec2-secret-key=XXXXX”, “amazonec2-ssh-user=ubuntu”, “amazonec2-region=us-east-2”, “amazonec2-instance-type=m4.xlarge”, “amazonec2-ami=ami-XXXXX”, “amazonec2-root-size=50”, “amazonec2-zone=a”, “amazonec2-userdata=/etc/gitlab-runner/user-data.sh”, “amazonec2-use-ebs-optimized-instance=true”, ]
Docker Daemon Config
The following is the contents of /etc/docker/daemon.json on all CI machines. It configures the Docker daemon to use Google’s mirror of Dockerhub when Dockerhub is down or having reliability issues. It also limits the size of Docker logs (a source of many filled disks).
{
"registry-mirrors": ["https://mirror.gcr.io"],
"log-driver": "json-file",
"log-opts": {"max-size": "10m", "max-file": "3"}
}
Metrics
The following table contains some metrics on the cost of our configuration over the past six months:
| Instance Type | Instance Count | Total Job Hours | Cost | Cost Relative to On Demand, Always On, 4 | Turnaround Time Relative to On Demand, Always On, 4 |
|---|---|---|---|---|---|
| On demand, Always On | 4 | 1938.74 | 3423.84 | 100% | 100% |
| On demand, As Needed | 80 Max | 1938.74 | 378.87 | 11.07% | 0.05% |
| Spot | 80 Max | 1938.74 | 80.69 | 2.36% | 0.05% |
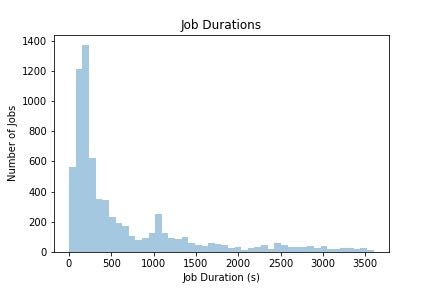
The following histogram shows the durations of jobs ran since we started using CI:
The following plot shows the maximum number of jobs we’ve had running at once, over time:
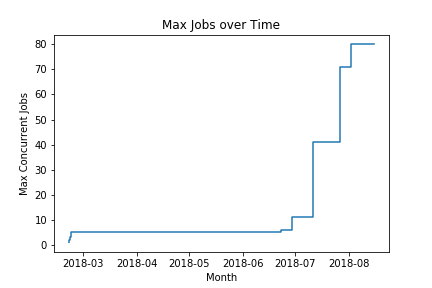
One thing these metrics do not capture is the impact of checking the availability of instance_profile has on job durations.
Before running this check, job startup times would often go as high as 6 minutes and would occasionally end up stuck in a “Pending” state due to a lack of available compute.
Job startup times now rarely exceed 1 minute and they do not get stuck “Pending”.
Changes since this was started
Docker Machine Gitlab MR
This MR, which was added in Gitlab 11.1, raised the number of CI jobs we could have running at once to at least 80. Given the performance claims and the number of jobs we could run at once before being rate limited by AWS before this MR was merged, I would guess we could run somewhere between 200 and 250 jobs at once before being rate limited by AWS.
https://gitlab.com/gitlab-org/gitlab-runner/merge_requests/909
Meltano
While working on this project, Gitlab announced their Meltano project. While the goal of Meltano might not be enabling the use of CI to process versioned data, that will almost certainly be a component. As the purpose of this CI configuration was to allowing us to use CI to process versioned data, I expect that the performance and capabilities of this CI configuration will increase as bugs related to Gitlab Runner and Docker Machine are addressed for Meltano.
https://about.gitlab.com/2018/08/01/hey-data-teams-we-are-working-on-a-tool-just-for-you/
Spot Pricing Change
AWS recently changed how they calculate the price of spot instances, smoothing price fluctuations.
While this change reduces the benefit of the approach of finding the optimal instance_profile to use to run instances, the approach of finding the optimal instance_profile still allows us to use the cheapest instances meeting our compute, startup-time and compute capacity requirements.
https://aws.amazon.com/blogs/compute/new-amazon-ec2-spot-pricing/
So…
That’s left us with more than we need to get our jobs ran in a timely manner.
This paragraph was initially going to be:
There are a few yet-to-be-a-problem cases these scripts have not addressed, such as ignoring sold out instance-region-zone combinations and automatically restarting jobs that are cancelled due to instance price increases and automating the generation (and use of) new pre-loaded AMIs periodically.
but, as our needs grew, all those problems had to be addressed.
See https://github.com/twosixlabs/gitlab-ci-scripts for a more copy-paste friendly version of the scripts on this page.



Bridging the gap between the impossible and the practical with innovative technology solutions in cyber, data science, mobile, microelectronics and information operations and a full spectrum of products and capabilities to advance national security missions.